Last updated: April 2026 — The Paradigm API evolves fast. Always check the latest API reference and prefer more recent cookbook entries when available.
Overview
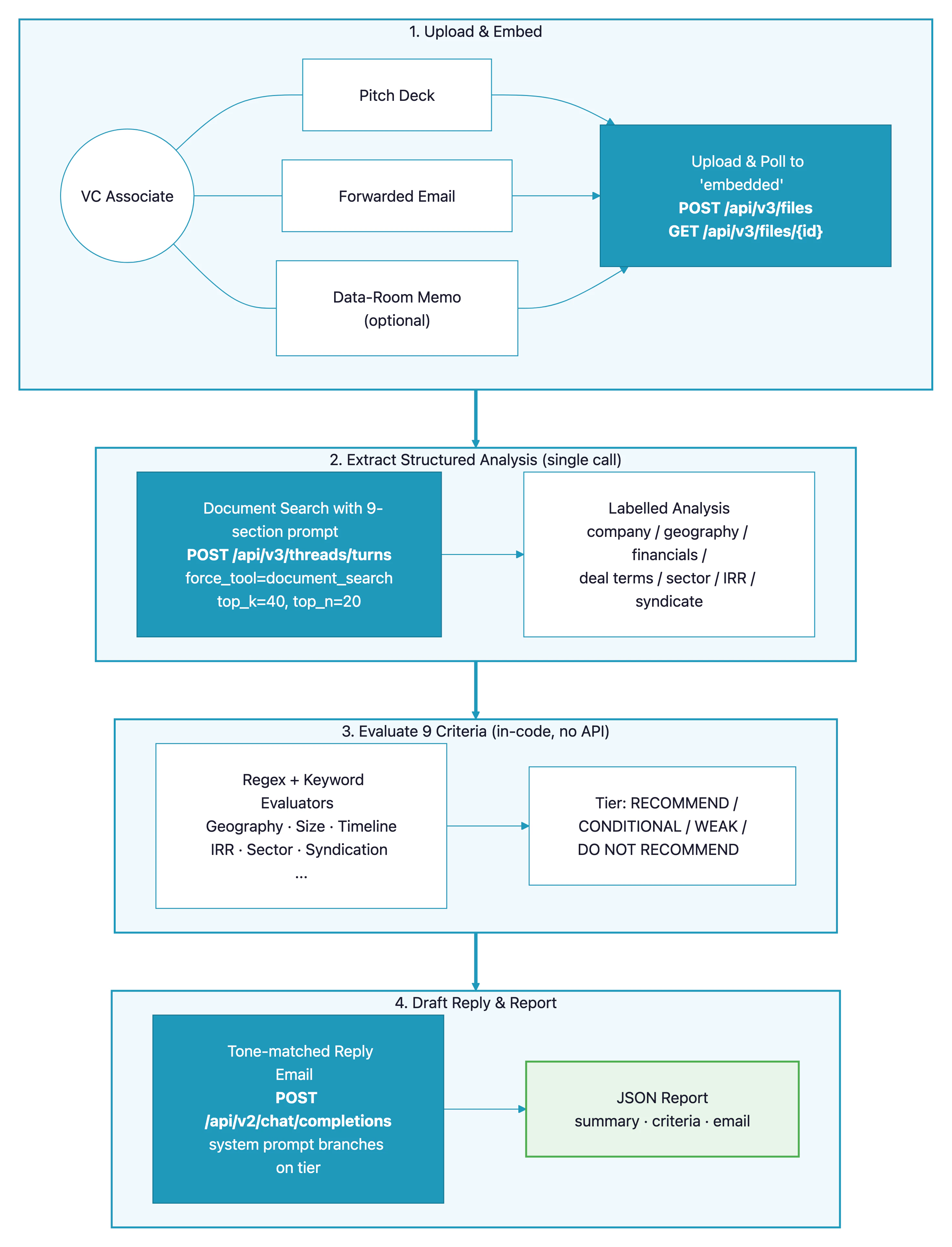
A VC associate’s morning inbox is full of investment teasers — pitch decks, forwarded emails, data-room memos. Before any meeting gets booked, someone has to check the opportunity against the fund’s investment criteria: is it in the right sector? Is the ticket size in range? Is the timeline workable? This cookbook builds a pipeline that uploads the documents to Paradigm, extracts a structured analysis with a singledocument_search call, evaluates a rubric of nine screening criteria in code, and drafts a reply email whose tone matches the outcome.
The pattern fits any rubric-based triage workflow where you want one LLM extraction plus deterministic scoring: procurement bid screening, grant-application triage, RFP filtering, M&A pipeline ranking.
Demo
See the pipeline review a pitch deck and forwarded email, score them against nine criteria, and draft a reply email tuned to the outcome:How It Works
- The user uploads one or more investment-opportunity documents (pitch deck, forwarded email, data-room memo).
- Each document is uploaded to Paradigm and polled until it reaches
embeddedstatus. - A single agent-based
document_searchcall extracts a structured, section-labelled analysis of the opportunity — company, geography, financials, deal terms, sector, IRR, syndicate. - Nine deterministic criterion evaluators run in code, with no further API calls against the extracted analysis. Each returns
METorNOT METwith a short justification. - The criteria are summed into one of four recommendation tiers (
RECOMMEND,CONDITIONAL RECOMMEND,WEAK RECOMMEND,DO NOT RECOMMEND). - A single
chat/completionscall drafts a reply email whose tone branches on the tier — a meeting request for a recommend, a follow-up with specific questions for a conditional, a diplomatic decline for a no.
Prerequisites
- A Paradigm API key (get one here)
- Python 3.10+
- One or more investment-opportunity documents (sample PDF and DOCX included in the GitHub repo)
API Endpoints Used
Step-by-Step Implementation
Step 1: Pick a Workspace and Upload
Paradigm’s/api/v3/files endpoint uploads into a specific workspace. Rather than hard-code one, we discover a sensible default at startup (personal → private → company → first available) and cache it on the client. Uploads are asynchronous: each file cycles pending → parsing → embedded, so we poll GET /api/v3/files/{id} until it’s ready.
For a small demo (1–3 files) the defaults are fine. For batch processing dozens of documents in parallel, raise
POLL_TIMEOUT and lower POLL_INTERVAL, or move to a background-job pattern.Step 2: Extract Everything in One Structured Query
Instead of making one call per criterion, we write a single “extraction prompt” that asks Paradigm to produce a section-labelled analysis covering every piece of information we care about. The prompt explicitly asks the model to write “not disclosed” when a section is missing — that way we can detect gaps deterministically downstream.Step 3: Force the Agent to Search, and Retrieve Broadly
Thedocument_search tool on the V3 threads endpoint does the actual retrieval. Two flags matter here. First, force_tool="document_search" prevents the agent from answering from general knowledge — it must use the uploaded files. Second, we lift top_k and top_n well above the defaults so a single query can pull enough context to answer all nine sections at once.
Step 4: Define the Rubric as Data
Each criterion is one entry in a single module — label, evaluator function, threshold constants at the top. Keeping the rubric close to the top ofsrc/pipeline.py means a fund operator can audit or edit it without touching the API plumbing.
Step 5: Write Deterministic Evaluators
Each criterion is a small Python function that reads the extracted analysis and returnsMET or NOT MET with an explanation. No further LLM calls — that keeps the rubric cheap, fast, and testable.
Step 6: Roll Up to a Recommendation Tier
Tally the criteria met, then pick one of four tiers. The break-points (7 and 5 out of 9) are the client’s real policy — tune for your own shop.
Step 7: Draft a Tone-Matched Reply Email
The final call is a single Chat Completion. The system prompt is fixed (“5-8 sentences, no emojis, no marketing”), and the user prompt branches on the recommendation tier — a positive, a mixed, or a diplomatic-decline brief. This separation keeps the voice consistent while letting the content adapt to the outcome.Step 8: Assemble the Report
The final report bundles the extracted analysis, per-criterion results, the recommendation, and the drafted email into one JSON payload — ready for a CI step, a Slack notification, or a CRM write-back.Complete Code
Full source code
Clone the repository to run the complete pipeline with sample opportunity documents.
API Reference
Full Paradigm API documentation.
Customization
Adding Your Own Criterion
Each criterion is a small function plus an entry in the order and label maps. Steps to add one:- Add the key to
CRITERIA_ORDERand a label toCRITERION_LABELS. - Write a
_check_<name>function that returns aCriterionResult. - Register it in
_EVALUATORS. - (Optional) Add anything the new check needs to
EXTRACTION_QUERYso the analysis includes it.
Best Practices
- Extract once, evaluate many times — a single big extraction query is cheaper and more consistent than one call per criterion. Ask the LLM for everything up front, then apply rubric logic in code where it’s deterministic and testable.
- Ask the model to label gaps explicitly — the phrase “state ‘not disclosed’ explicitly rather than omitting the section” in the extraction prompt is load-bearing. It turns missing information into a detectable signal instead of silently passing through.
- Keep evaluators deterministic — regex and keyword matching on an LLM-extracted structured analysis gives you auditable decisions. If a deal is rejected, the evaluator name and explanation tell you exactly why.
- Branch the reply-email system prompt on the outcome — keep the voice constant, change the content. Three concise branches (positive / mixed / decline) produce consistently professional emails without brittle templating.
- Keep thresholds and sector lists at the top of the pipeline module — your policy will evolve; your operators shouldn’t need to read Python to adjust a number.
- Lift
top_k/top_nfor rich extraction queries — the defaults are tuned for short Q&A. When you ask for nine sections in one breath, give the retriever enough context to find it all.