Last updated: April 2026 — The Paradigm API evolves fast. Always check the latest API reference and prefer more recent cookbook entries when available.
Overview
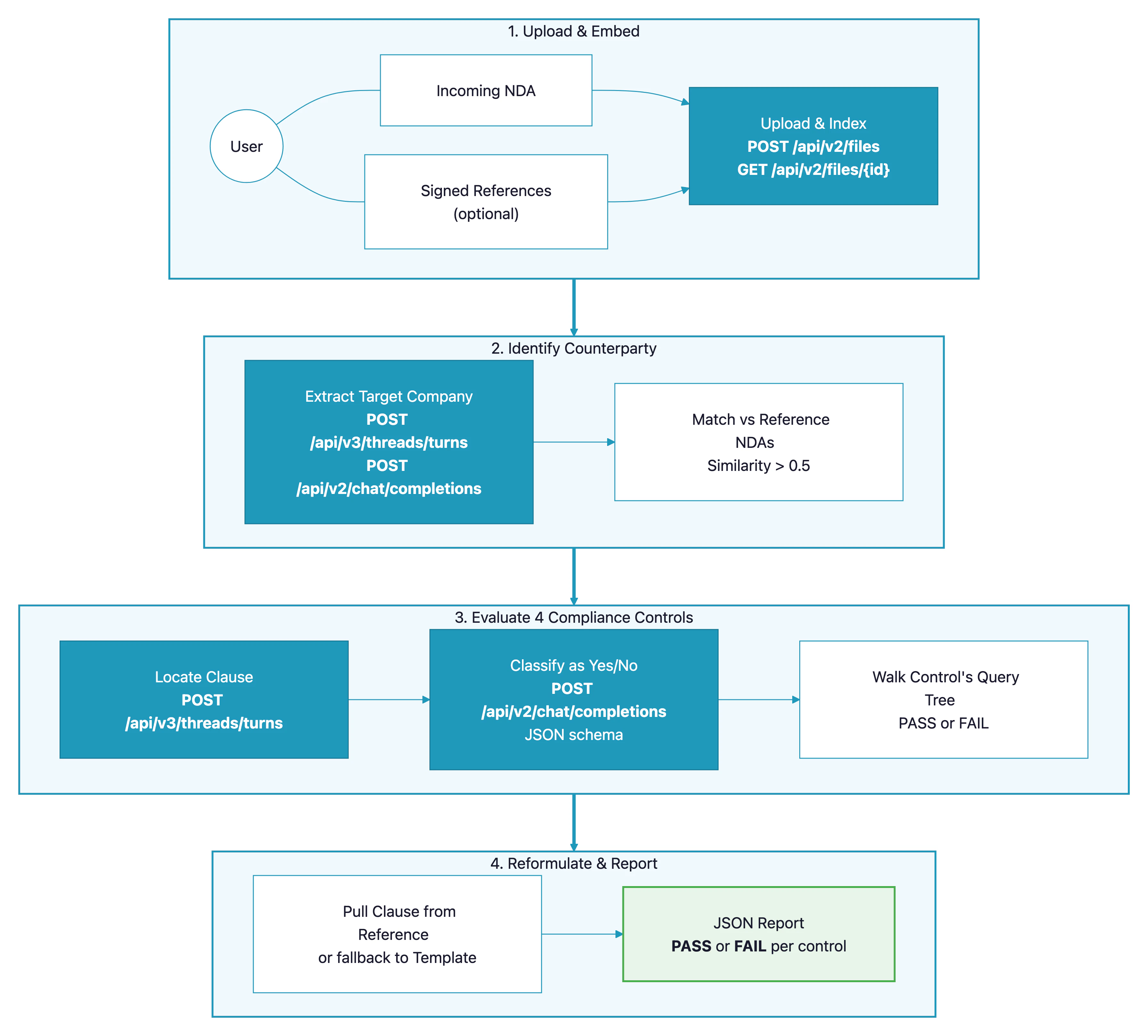
Legal teams spend hours reviewing incoming NDAs against an internal policy — checking that liability is properly capped, that disclosure carve-outs exist, that the return-of-information clause has the right exceptions. This cookbook shows how to build a pipeline that uploads an NDA to Paradigm, runs a configurable set of legal controls over it, and for every failing control proposes a rewording sourced from a previously signed NDA (or, if none matches, a default template). The pattern generalises to any contract-review workflow: MSAs, supplier agreements, DPAs, employment contracts. Anywhere a policy check and a suggested fix would save a reviewer time.Demo
See the pipeline reviewing a sample NDA, failing two of four controls, and proposing rewordings pulled from a previously signed reference:How It Works
- The user uploads an incoming NDA, plus zero or more previously signed reference NDAs.
- Each document is uploaded to Paradigm and indexed via embedding.
- The counterparty (Target Company) is extracted from each document and used to match the incoming NDA with the most similar reference.
- Four compliance controls are run against the incoming NDA. Each control is a small tree of yes/no legal questions — each question is answered by combining an agent-based Document Search (to locate the clause) with a structured Chat Completion (to classify it and return the supporting quote).
- For every control that fails, the same extraction flow is applied to the matched reference NDA to propose a rewording. If no reference matched, a default template is used instead.
- Results are compiled into a JSON report with per-control status, extracted quotes, and proposed rewordings.
Prerequisites
- A Paradigm API key (get one here)
- Python 3.10+
- At least one NDA to review (sample NDAs are included in the GitHub repo)
- Optional: previously signed NDAs to use as reformulation sources
API Endpoints Used
Step-by-Step Implementation
Step 1: Upload and Wait for Embedding
Unlike upload-session–based workflows, NDAs are uploaded as single files viaPOST /api/v2/files. Because Document Search requires the document to be fully embedded, we poll GET /api/v2/files/{id} until its status flips to embedded.
Step 2: Ask a Yes/No Legal Question
Every compliance check comes down to the same two-step pattern: first a Document Search surfaces the relevant clause, then a structured Chat Completion classifies it and returns the supporting quote. The JSON schema guarantees we always get a predictable shape back.Step 3: Use force_tool and response_format for Structure
Two Paradigm features do the heavy lifting here. First, force_tool: "document_search" on the V3 threads endpoint guarantees the model does a RAG lookup over the specified file rather than answering from general knowledge:
response_format with a JSON schema on chat/completions guarantees the classification answer is a valid, parseable object — no regex-wrangling of free-text responses:
Step 4: Model the Controls as Query Trees
Each compliance control is a tree of yes/no questions with branching rules. Keeping the controls as data — not code — makes them trivial to audit, tune, or hand off to a non-engineer._run_control. Control 1 for example reads: “if a liability clause exists, then it must be capped to direct damages; otherwise the NDA must be governed by French law.”
Step 5: Extract the Counterparty for Matching
Before running controls we identify the Target Company in the NDA. In an M&A context three parties may appear — the Receiving Party (the buyer), a Financial Advisor intermediary, and the Target Company whose information is being shared. We want the Target Company, not the other two. A carefully-written prompt plus a one-field JSON schema keeps the output clean:difflib.SequenceMatcher (a drop-in stand-in for PostgreSQL trigram similarity).
Step 6: Reformulate Failing Clauses
When a control fails, we propose a fix. The fallback chain is: “try to pull the equivalent clause from the matched reference NDA; if nothing usable comes back, use a pre-written template.”Step 7: Compile the Report
The final report bundles the counterparty, the matched reference, and oneControlResult per control (status, queries with quotes, proposed reformulation). A top-level summary makes it trivial to wire the review into a CI check or a dashboard.
Complete Code
Full source code
Clone the repository to run the complete pipeline with sample NDAs.
API Reference
Full Paradigm API documentation.
Customization
Adding Your Own Control
Each control is one entry in theCONTROLS list. Steps to add one:
- Define the queries — one yes/no legal question per node in your decision tree.
- Add branching logic to
_run_control— under which combination of answers is the controlPASSvsFAIL, and which query’s template is used for reformulation. - Write a default template — the fallback wording used when no reference NDA matches.
Best Practices
- Keep controls as data, not code — putting the query text and templates in a list (not spread through functions) makes compliance review a task your legal team can audit directly. Small wins for lawyers are big wins for the pipeline.
- Always use
force_tool: "document_search"for clause lookups — it forces Paradigm to cite the actual document rather than rely on general knowledge, which matters enormously for legal review. - Use
response_formatwith a JSON schema for classification — free-text parsing of “yes/no plus quote” is fragile; schema-enforced JSON is bulletproof. - Prefer reference-sourced rewordings over templates — language the counterparty has already signed is far easier to accept than a generic template clause. Fall back to templates only when no reference matched.
- Match counterparties, not filenames — extracting the Target Company before matching means you can use an inventory of hundreds of signed NDAs without worrying about how they were named. A loose similarity threshold (0.5) is forgiving of naming variations.
- Validate the extracted counterparty — M&A NDAs often involve three parties; a cheap schema-backed extractor with explicit “exclude these roles” rules in the description field saves expensive re-runs.