Last updated: April 2026 — The Paradigm API evolves fast. Always check the latest API reference and prefer more recent cookbook entries when available.
Overview
Verifying that information is consistent across a set of related documents — procurement forms, contracts, bank details, identity declarations — is tedious, error-prone, and expensive when done manually. This cookbook shows how to build an automated verification pipeline that uploads documents to Paradigm, extracts specific fields using Document Search, and cross-references them using Chat Completions with structured prompts. The pattern is applicable to any multi-document verification workflow: compliance audits, insurance claims processing, loan applications, supplier onboarding, and more.Demo
See the pipeline in action — uploading documents, running automated checks, and generating a verification report:How It Works
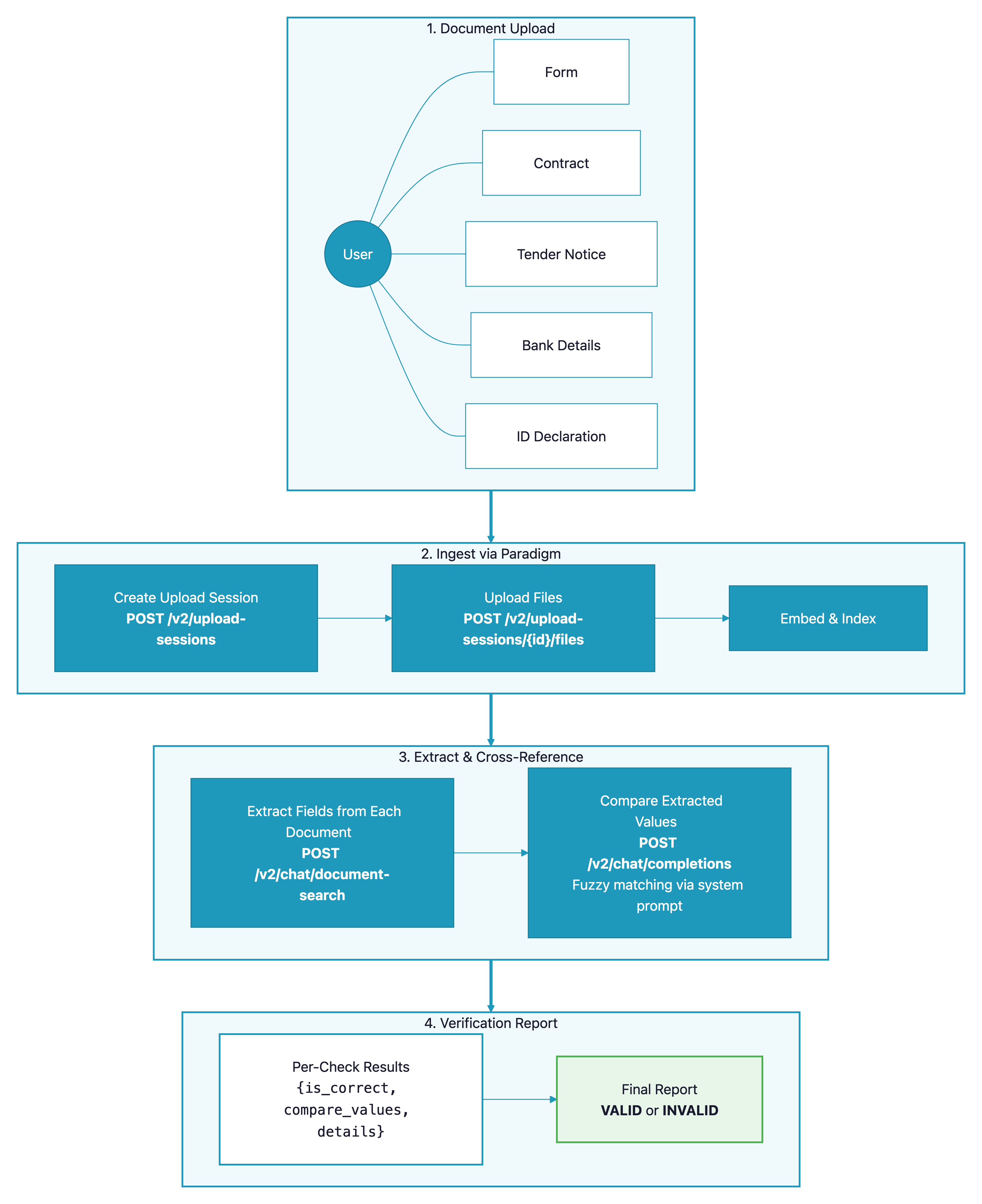
- The user uploads a set of related documents (e.g., a form, a contract, bank details, an identity declaration).
- Documents are ingested into Paradigm via the Upload Sessions API.
- For each verification check, specific fields are extracted from the relevant documents using Document Search.
- Extracted fields are compared using Chat Completions with a structured system prompt that handles fuzzy matching (typos, formatting differences, abbreviations).
- Each check returns a structured result:
is_correct, the compared values, and details explaining the decision. - All results are compiled into a verification report.
Prerequisites
- A Paradigm API key (get one here)
- Python 3.10+
- Documents to verify (sample documents are included in the GitHub repo)
API Endpoints Used
Step-by-Step Implementation
Step 1: Set Up the Paradigm Client
Create a wrapper around the Paradigm API. This client handles authentication, document upload, field extraction, and cross-referencing.Step 2: Upload Documents
Documents must be uploaded to Paradigm before they can be queried. The Upload Sessions API manages the ingestion pipeline — you create a session, upload files to it, then close the session to trigger embedding.Documents must be fully embedded before they can be queried. Embedding time depends on document size and complexity — typically a few seconds to a few minutes.
Step 3: Extract Fields with Document Search
Once documents are embedded, use Document Search to extract specific fields. Thequery parameter is a natural language question — Paradigm searches the document and returns the relevant content.
Step 4: Cross-Reference Fields with Chat Completions
This is the core of the verification pipeline. After extracting the same field from two different documents, use Chat Completions with a structured system prompt to compare them. The system prompt handles real-world messiness: typos, formatting differences, abbreviations, missing accents.Step 5: Define Verification Checks
Each check is a function that extracts a field from two documents and compares them. Here’s the pattern — repeat it for each field you need to verify.Step 6: Orchestrate All Checks
Run all verification checks in parallel for speed, then compile results into a report.Step 7: Generate a Verification Report
Compile all results into a structured report. The example below generates a simple summary — in production, you might generate a PDF or write to a database.Complete Code
Full source code
Clone the repository to run the complete pipeline with sample documents.
API Reference
Full Paradigm API documentation.
Customization
Adapt this pipeline to your own verification needs:Adding Your Own Checks
To add a new verification check, follow this three-step pattern:- Extract the field from document A using
search_document()with a clear natural language query - Extract the same field from document B
- Compare using
cross_reference()— the system prompt handles fuzzy matching
Best Practices
- Use
VisionDocumentSearchfor scanned documents — standardDocumentSearchworks for native PDFs, but scanned documents and images need the vision tool for reliable extraction. - Keep extraction queries specific — “What is the IBAN?” works better than “Extract all banking information.” One field per query yields more reliable results.
- Tune the system prompt for your domain — the fuzzy matching rules should reflect your business requirements. Financial data may need exact matching; names and addresses typically need fuzzy matching.
- Run checks in parallel — each check is independent, so use threading to process them concurrently. Add a small delay between batches if you hit rate limits.
- Log intermediate results — when a check fails, having the raw extracted values from both documents makes debugging much faster.