Derniere mise a jour : Avril 2026 — L’API Paradigm evolue rapidement. Consultez toujours la derniere reference API et privilegiez les cookbooks les plus recents.
Presentation
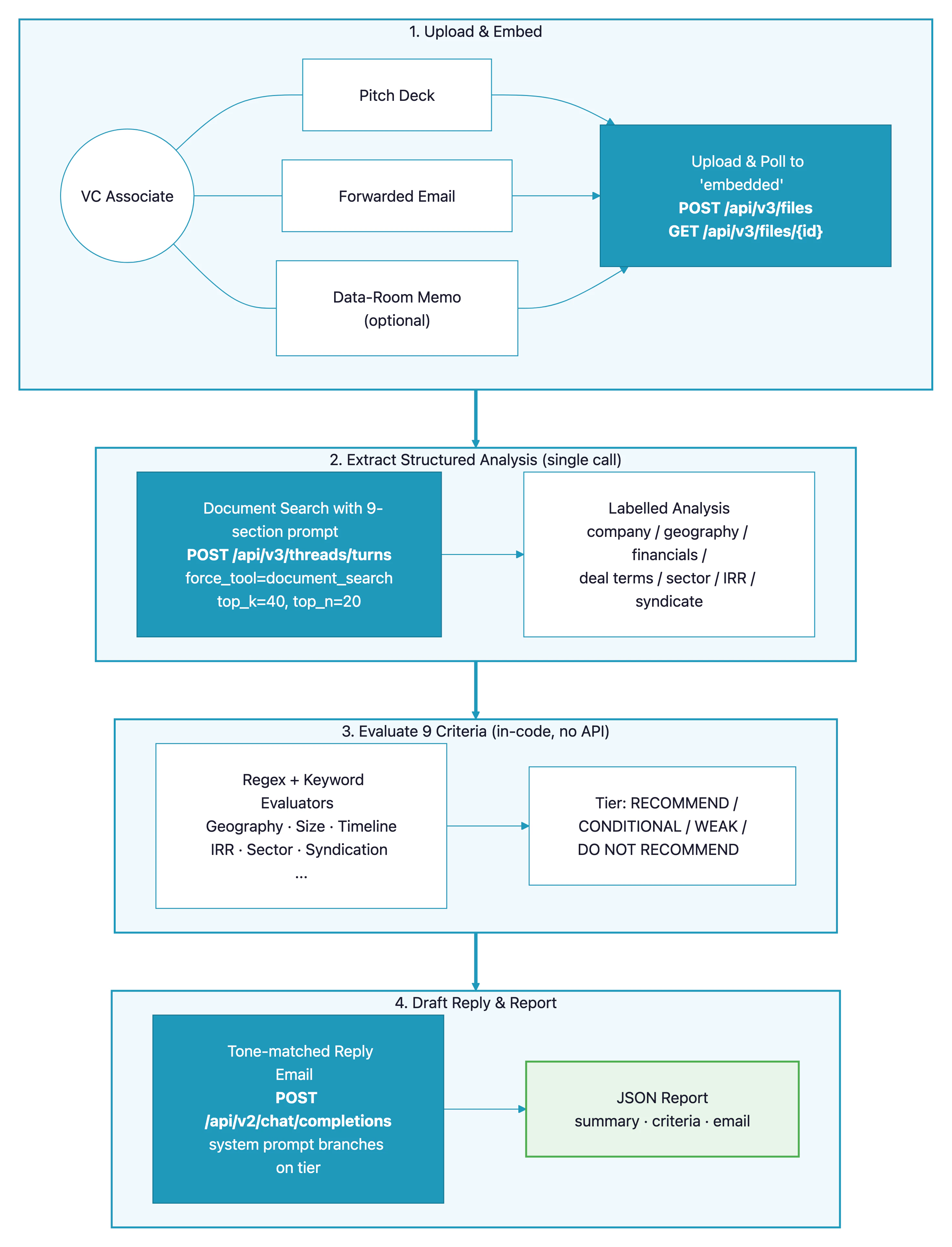
La boite de reception d’un associe VC est pleine de teasers d’investissement — pitch decks, emails transferes, memos de data-room. Avant de fixer le moindre rendez-vous, quelqu’un doit verifier l’opportunite au regard des criteres d’investissement du fonds : secteur, taille de ticket, calendrier. Ce cookbook construit un pipeline qui charge les documents dans Paradigm, extrait une analyse structuree en un seul appeldocument_search, evalue une grille de neuf criteres en code, et redige une reponse email dont le ton correspond au resultat du filtrage.
Le pattern s’applique a tout workflow de triage base sur une grille qui combine une extraction LLM et un scoring deterministe : filtrage de reponses a appel d’offres, triage de candidatures a subvention, filtrage de RFP, classement de pipeline M&A.
Demo
Decouvrez le pipeline analysant un pitch deck et un email transfere, les evaluant contre neuf criteres, et redigeant une reponse email au ton adapte au resultat :Fonctionnement
- L’utilisateur charge un ou plusieurs documents d’opportunite (pitch deck, email transfere, memo de data-room).
- Chaque document est charge dans Paradigm et interroge jusqu’a ce qu’il atteigne le statut
embedded. - Un unique appel
document_searchagentique extrait une analyse structuree et libellee de l’opportunite — societe, geographie, financiers, conditions de deal, secteur, TRI, syndicat. - Neuf evaluateurs de criteres deterministes s’executent en code, sans appel API supplementaire sur l’analyse extraite. Chacun retourne
METouNOT METavec une courte justification. - Les criteres sont agreges en l’un des quatre paliers de recommandation (
RECOMMEND,CONDITIONAL RECOMMEND,WEAK RECOMMEND,DO NOT RECOMMEND). - Un unique appel
chat/completionsredige une reponse email dont le ton s’adapte au palier — demande de rendez-vous pour un recommend, relance avec questions specifiques pour un conditional, refus diplomatique pour un no.
Prerequis
- Une cle API Paradigm (obtenir une cle)
- Python 3.10+
- Un ou plusieurs documents d’opportunite (PDF et DOCX d’exemple fournis dans le depot GitHub)
Endpoints API utilises
Implementation etape par etape
Etape 1 : Choisir un workspace et charger
L’endpoint/api/v3/files de Paradigm charge dans un workspace specifique. Plutot que d’en coder un en dur, on decouvre un defaut raisonnable au demarrage (personal → private → company → premier disponible) et on le met en cache sur le client. Les chargements sont asynchrones : chaque fichier passe par pending → parsing → embedded, on interroge donc GET /api/v3/files/{id} jusqu’a ce qu’il soit pret.
Pour une petite demo (1 a 3 fichiers) les defauts suffisent. Pour traiter des dizaines de documents en parallele, augmentez
POLL_TIMEOUT et baissez POLL_INTERVAL, ou passez a un pattern de job en arriere-plan.Etape 2 : Tout extraire en une seule requete structuree
Au lieu de faire un appel par critere, on redige une unique “prompt d’extraction” qui demande a Paradigm de produire une analyse libellee par section couvrant toutes les informations dont on a besoin. La prompt demande explicitement au modele d’ecrire “not disclosed” quand une section manque — ainsi, on peut detecter les trous de facon deterministe en aval.Etape 3 : Forcer la recherche agentique et elargir la recuperation
L’outildocument_search de l’endpoint V3 threads effectue la recuperation reelle. Deux drapeaux comptent ici. Premierement, force_tool="document_search" empeche l’agent de repondre depuis sa connaissance generale — il doit utiliser les fichiers charges. Deuxiemement, on remonte top_k et top_n bien au-dessus des defauts pour qu’une seule requete puisse tirer suffisamment de contexte pour repondre aux neuf sections d’un coup.
Etape 4 : Definir la grille comme de la donnee
Chaque critere est une entree d’un unique module — libelle, fonction d’evaluation, constantes de seuils en haut. Garder la grille au sommet desrc/pipeline.py permet a un operateur du fonds de l’auditer ou de la modifier sans toucher a la plomberie API.
Etape 5 : Rediger des evaluateurs deterministes
Chaque critere est une petite fonction Python qui lit l’analyse extraite et retourneMET ou NOT MET avec une explication. Aucun appel LLM supplementaire — cela garde la grille peu couteuse, rapide et testable.
Etape 6 : Agreger vers un palier de recommandation
Comptez les criteres respectes, puis choisissez l’un des quatre paliers. Les seuils (7 et 5 sur 9) refletent la politique reelle du client — ajustez pour votre propre organisation.
Etape 7 : Rediger une reponse email au ton adapte
Le dernier appel est un unique Chat Completion. Le prompt systeme est fixe (“5 a 8 phrases, pas d’emojis, pas de marketing”), et le prompt utilisateur branche sur le palier de recommandation — un brief positif, mixte, ou de refus diplomatique. Cette separation garde la voix constante tout en laissant le contenu s’adapter au resultat.Etape 8 : Assembler le rapport
Le rapport final regroupe l’analyse extraite, les resultats critere par critere, la recommandation et l’email redige dans un unique payload JSON — pret pour une etape CI, une notification Slack ou une ecriture dans un CRM.Code complet
Code source complet
Clonez le depot pour executer le pipeline complet avec les documents d’exemple.
Reference API
Documentation complete de l’API Paradigm.
Personnalisation
Ajouter votre propre critere
Chaque critere est une petite fonction plus une entree dans les maps d’ordre et de libelles. Etapes pour en ajouter un :- Ajoutez la cle dans
CRITERIA_ORDERet un libelle dansCRITERION_LABELS. - Redigez une fonction
_check_<nom>qui retourne unCriterionResult. - Enregistrez-la dans
_EVALUATORS. - (Optionnel) Ajoutez dans
EXTRACTION_QUERYce dont votre nouveau check a besoin, pour que l’analyse l’inclue.
Bonnes pratiques
- Extraire une fois, evaluer plusieurs fois — une unique grande requete d’extraction coute moins cher et est plus coherente qu’un appel par critere. Demandez tout au LLM d’emblee, puis appliquez la logique de la grille en code, la ou elle est deterministe et testable.
- Demandez au modele de libeller les trous explicitement — la phrase “state ‘not disclosed’ explicitly rather than omitting the section” dans la prompt d’extraction est cruciale. Elle transforme l’information manquante en signal detectable plutot qu’en passage silencieux.
- Gardez les evaluateurs deterministes — regex et keyword matching sur une analyse structuree extraite par LLM donne des decisions auditables. Si une opportunite est rejetee, le nom de l’evaluateur et son explication vous disent exactement pourquoi.
- Branchez le prompt systeme de l’email de reponse sur le resultat — gardez la voix constante, changez le contenu. Trois branches concises (positive / mixte / refus) produisent des emails toujours professionnels sans templating fragile.
- Gardez les seuils et les listes sectorielles en haut du module pipeline — votre politique va evoluer ; vos operateurs ne devraient pas avoir a lire du Python pour ajuster un chiffre.
- Remontez
top_k/top_npour les requetes d’extraction riches — les defauts sont cales pour des Q&A courts. Quand vous demandez neuf sections d’un coup, donnez au retriever assez de contexte pour tout trouver.