Derniere mise a jour : Avril 2026 — L’API Paradigm evolue rapidement. Consultez toujours la derniere reference API et privilegiez les cookbooks les plus recents.
Presentation
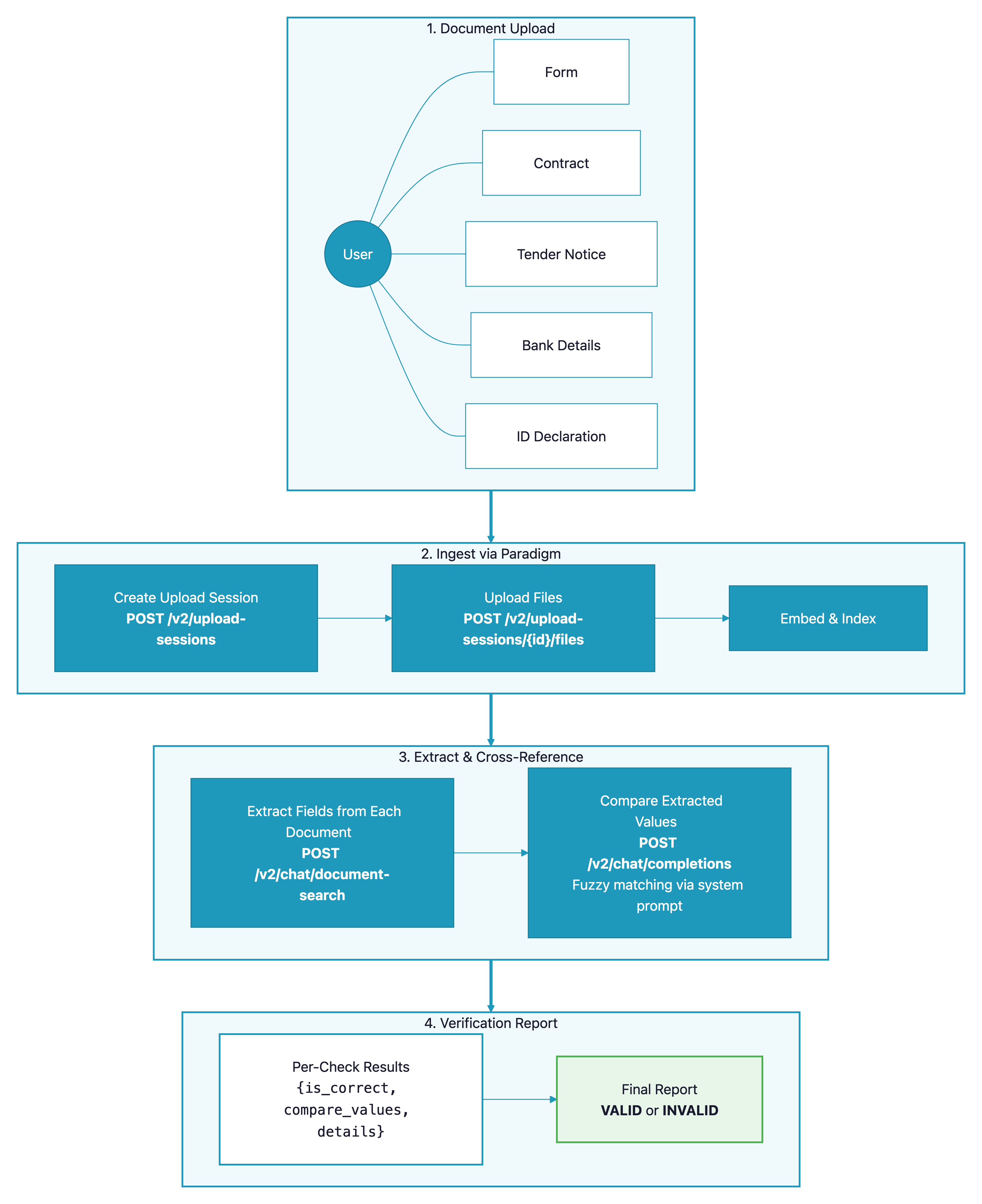
Verifier la coherence des informations entre plusieurs documents lies — formulaires de marches publics, contrats, releves bancaires, declarations d’identite — est un travail fastidieux, source d’erreurs et couteux lorsqu’il est realise manuellement. Ce cookbook montre comment construire un pipeline de verification automatise qui charge des documents dans Paradigm, extrait des champs specifiques via Document Search, et les recoupe grace a Chat Completions avec des prompts structures. Ce pattern s’applique a tout workflow de verification multi-documents : audits de conformite, traitement de sinistres d’assurance, demandes de prets, integration de fournisseurs, et plus encore.Demo
Decouvrez le pipeline en action — chargement de documents, execution des controles automatiques et generation d’un rapport de verification :Fonctionnement
- L’utilisateur charge un ensemble de documents lies (ex. : un formulaire, un contrat, un RIB, une declaration).
- Les documents sont ingeres dans Paradigm via l’API Upload Sessions.
- Pour chaque controle, des champs specifiques sont extraits des documents concernes via Document Search.
- Les champs extraits sont compares via Chat Completions avec un prompt systeme structure qui gere la correspondance approximative (fautes, differences de format, abreviations).
- Chaque controle retourne un resultat structure :
is_correct, les valeurs comparees, et une explication de la decision. - Tous les resultats sont compiles dans un rapport de verification.
Prerequis
- Une cle API Paradigm (obtenir une cle)
- Python 3.10+
- Documents a verifier (des documents d’exemple sont fournis dans le depot GitHub)
Endpoints API utilises
Implementation etape par etape
Etape 1 : Configurer le client Paradigm
Creez un wrapper autour de l’API Paradigm. Ce client gere l’authentification, le chargement de documents, l’extraction de champs et le recoupement.Etape 2 : Charger les documents
Les documents doivent etre charges dans Paradigm avant de pouvoir etre interroges. L’API Upload Sessions gere le pipeline d’ingestion — vous creez une session, chargez les fichiers, puis fermez la session pour declencher l’embedding.Les documents doivent etre entierement indexes avant de pouvoir etre interroges. Le temps d’indexation depend de la taille et de la complexite du document — en general quelques secondes a quelques minutes.
Etape 3 : Extraire des champs avec Document Search
Une fois les documents indexes, utilisez Document Search pour extraire des champs specifiques. Le parametrequery est une question en langage naturel — Paradigm recherche dans le document et retourne le contenu pertinent.
Etape 4 : Recouper les champs avec Chat Completions
C’est le coeur du pipeline de verification. Apres avoir extrait le meme champ de deux documents differents, utilisez Chat Completions avec un prompt systeme structure pour les comparer. Le prompt gere les imperfections du monde reel : fautes de frappe, differences de formatage, abreviations, accents manquants.Etape 5 : Definir les controles de verification
Chaque controle est une fonction qui extrait un champ de deux documents et les compare. Voici le pattern — repetez-le pour chaque champ a verifier.Etape 6 : Orchestrer tous les controles
Executez tous les controles en parallele pour gagner en rapidite, puis compilez les resultats dans un rapport.Etape 7 : Generer un rapport de verification
Compilez tous les resultats dans un rapport structure. L’exemple ci-dessous genere un resume simple — en production, vous pourriez generer un PDF ou ecrire en base de donnees.Code complet
Code source complet
Clonez le depot pour executer le pipeline complet avec des documents d’exemple.
Reference API
Documentation complete de l’API Paradigm.
Personnalisation
Adaptez ce pipeline a vos propres besoins de verification :Ajouter vos propres controles
Pour ajouter un nouveau controle de verification, suivez ce pattern en trois etapes :- Extraire le champ du document A avec
search_document()et une requete en langage naturel claire - Extraire le meme champ du document B
- Comparer avec
cross_reference()— le prompt systeme gere la correspondance approximative
Bonnes pratiques
- Utilisez
VisionDocumentSearchpour les documents scannes — leDocumentSearchstandard fonctionne pour les PDF natifs, mais les documents scannes et les images necessitent l’outil vision pour une extraction fiable. - Gardez les requetes d’extraction specifiques — “Quel est l’IBAN ?” fonctionne mieux que “Extraire toutes les informations bancaires.” Un champ par requete donne des resultats plus fiables.
- Adaptez le prompt systeme a votre domaine — les regles de correspondance approximative doivent refleter vos exigences metier. Les donnees financieres peuvent necessiter une correspondance exacte ; les noms et adresses necessitent generalement une correspondance approximative.
- Executez les controles en parallele — chaque controle est independant, utilisez le threading pour les traiter simultanement. Ajoutez un leger delai entre les lots si vous atteignez les limites de debit.
- Journalisez les resultats intermediaires — quand un controle echoue, avoir les valeurs brutes extraites des deux documents facilite grandement le debogage.